LSM树基础知识
/ 点击 / 阅读耗时 12 分钟LSM树简介
当我们讨论数据库存储数据的结构时,我们可以将各种存储结构分成两类:可变的数据结构和不可变的数据结构。可变的数据结构,意味着磁盘中的数据总是在原地被更新,典型的代表是到B树(或者B+树),它是MySQL中存储数据的一种结构。而不可变的数据结构,意味着磁盘中的数据不会被原地更新,典型的代表是LSM树,它是leveldb、rocksdb中存储数据的一种结构。
磁盘中的数据可否原地更新,给两种存储结构带来了截然不同的特性:
- 不同的写入性能:LSM树的数据文件仅支持追加,在新增、更新、删除的时候,只需要插入一条记录,不需要在原来的磁盘文件中进行查找,相当于减少了随机IO。相比于B树,写入性能得到提升。
- 不同的读取性能:LSM树查询数据需要遍历文件,直到发现数据的记录或查询到最后一个文件。因此,LSM树的查询性能不如B树。
- 不同的数据密度:B树为了减少新增数据导致的数据迁移,会在磁盘中预留位置。LSM树由于数据只会追加,不需要预留位置。因此,LSM树大部分时间具有更高的数据密度。
LSM树结构
目前,LSM树的实现基本都分成两个部分,内存部分和磁盘部分。内存部分,会使用B+树或者跳表,以保证良好的查询性能。磁盘部分,会使用B+树或者有序表(sorted-string table,SSTable)。
在查询上,LSM树可以支持点查和范围查。点查是从新到久,逐个文件查询。范围查则可以实现多个文件并行查找。
LSM树的合并算法
- leveling merge:每一层只有一个文件,合并的时候将上层的文件和下层的文件合并成一个新的文件。
- tiering merge:每一层有多个文件,合并的时候将上层的一部分文件合并成一个新的文件,放到下一层。
LSM分区
分区
- 每一层的文件分成不同的小文件,每个小文件维护一段key,合并的时候,会将有重叠部分的文件进行合并。
- 分区与合并算法是正交的,leveling和tiering都可以使用分区方法。
Leveling合并
LevelDB使用leveling合并加分区。

这种方式组织的文件,观察L-1层的部分文件和L层的部分文件,会发现它们之间有重叠的key。比如下面合Level1的0-30,和Level2的0-15,、16-32之间是有重叠的。
当Levle1的SSTabled需要合并的时候,会将Level1的0-30,和Level2的0-15,、16-32进行合并,最后得到新的文件,这些文件会放在L层。在合并过程中,如果发现合并后的文件过大,会将过大的SSTable,拆分成多个小的SSTable。
在LevelDB中,每个SSTable都有固定的大小。LevelDB使用轮询的策略,依次对SSTable进行合并。
Tiering分区合并
RocksDB使用tiering合并加分区。它有两种分区方法。
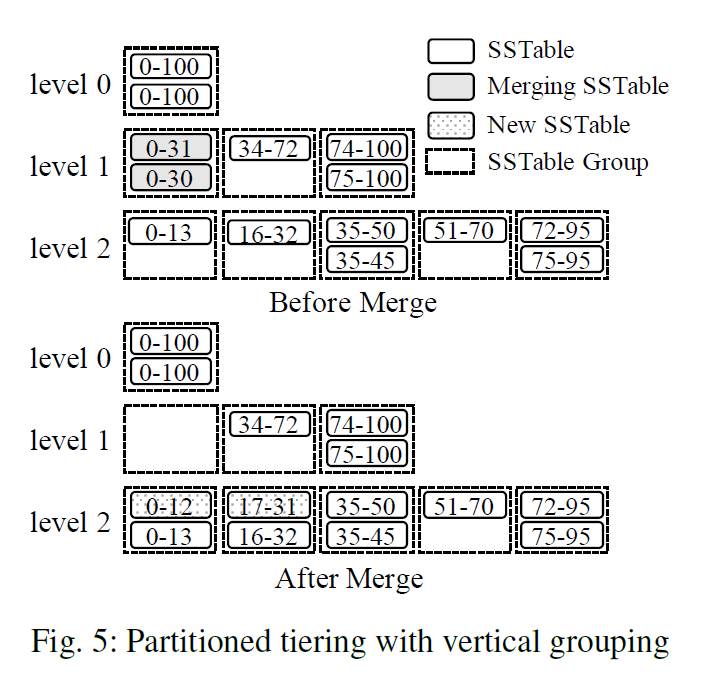
垂直分区
L层的文件有重叠的key,这些有重叠key的文件会组织成一个Group。合并的时候,这些重叠的文件会合并成新的文件,放到L+1层,然后和L+1层中重叠的文件组织成新的组。
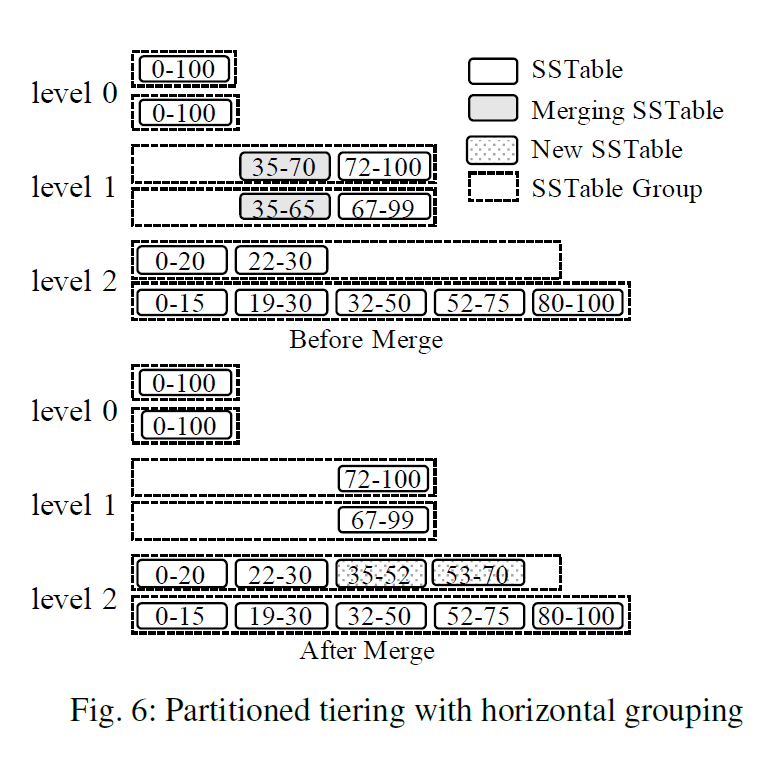
水平分区
每一层有多个不重叠的文件组成一个组,每一层只有一个活跃的组,这个组负责接受L-1层过来的合并文件,合并的时候每一组贡献一部分的文件,这些文件有重叠的key,这些key会被合并形成新的文件,然后放到L层。
并发控制和恢复
并发控制可以使用锁或者MVCC。由于LSM树针对一个key的修改不是原地更新,而是不断产生新的版本,因此MVCC在LSM树上实现比较简单。只要知道当前访问的版本即可。
但需要注意,在合并的时候,会删除老的SSTable,为了避免有访问的SSTable被删除,LSM树使用计数器来标识合并后的SSTable是否可以可以删除。
恢复使用WAL
LSM的优化方向
- 减少写放大:由于合并的存在,一个key的写入实际会变成多次写入。写放大影响性能和磁盘寿命。
- 合并优化:合并影响写性能,同时会导致文件系统cache失效。
- 硬件适配:最早的LSM是用来减少机械硬盘上,随机IO带来的影响,目前的磁盘有SSD、NVME盘,具有优化空间。
- 负载适配:可以针对读写比例的请求,进行针对性的优化
- 自动调优:RUM猜想,读优化、写优化和空间优化,三个不可能同时实现。是否存在自动调整参数,使其三者中取得均衡,是一种研究方向。
- 二级索引:原始的LSM只提供K-V结构,KKV也是新的研究方向。
写放大优化
Tiering分区
Tiering分区,可以优化写放大,不过会带了空间放大。
Leveling分区中,每段路由只能有一个sstable,合并的时候,然后上一层的sstable路由范围,覆盖到了下一层多个sstable,会导致这些sstable都要参与合并。
而在Tiering分区中,合并完全不需要下一层sstable的参与,合并完之后按大小拆分成多个sstable放到下一层即可。
跳层合并
一个key,如果它在某几层中都没有出现,那么合并过程中,它可以直接跳过这些层,合并到再次出现它的层(或者直接跳到最后一层)。
判断它在某层中是否出现,可以通过布隆过滤器。
这种思想的实现复杂,实际没什么应用。
冷热分离
如果一个key经常被更新,可以把它和其他key分开,放在单独的文件里,这里可以减少它的合并。
key是否是热key,可以依据它在memtable里面被访问的情况来区分。
更激进的做法是,热key可以采用原地更新的方式来更新,而非LSM这种追加更新的方式。
针对硬件的适配
针对大内存的适配
大内存中mutable过大,mutable采用B树的话,层数过多,查询延迟会变大。
解决方法是在内存中也分层,第一层可以直接用Hash结构,查询够快,后面几层可以使用B树。
针对SSD或NVM的优化
WiscKey的Value只保存在日志中,LSM中只保存Key和指向Value的指针。这样可以减少LSM树的大小,降低合并的压力。因为SSD的随机读性能也很好,所以WiscKey通过指针读取数据的性能也不错。